The Billion-Dollar Brain That Can’t Spell Its Own Name
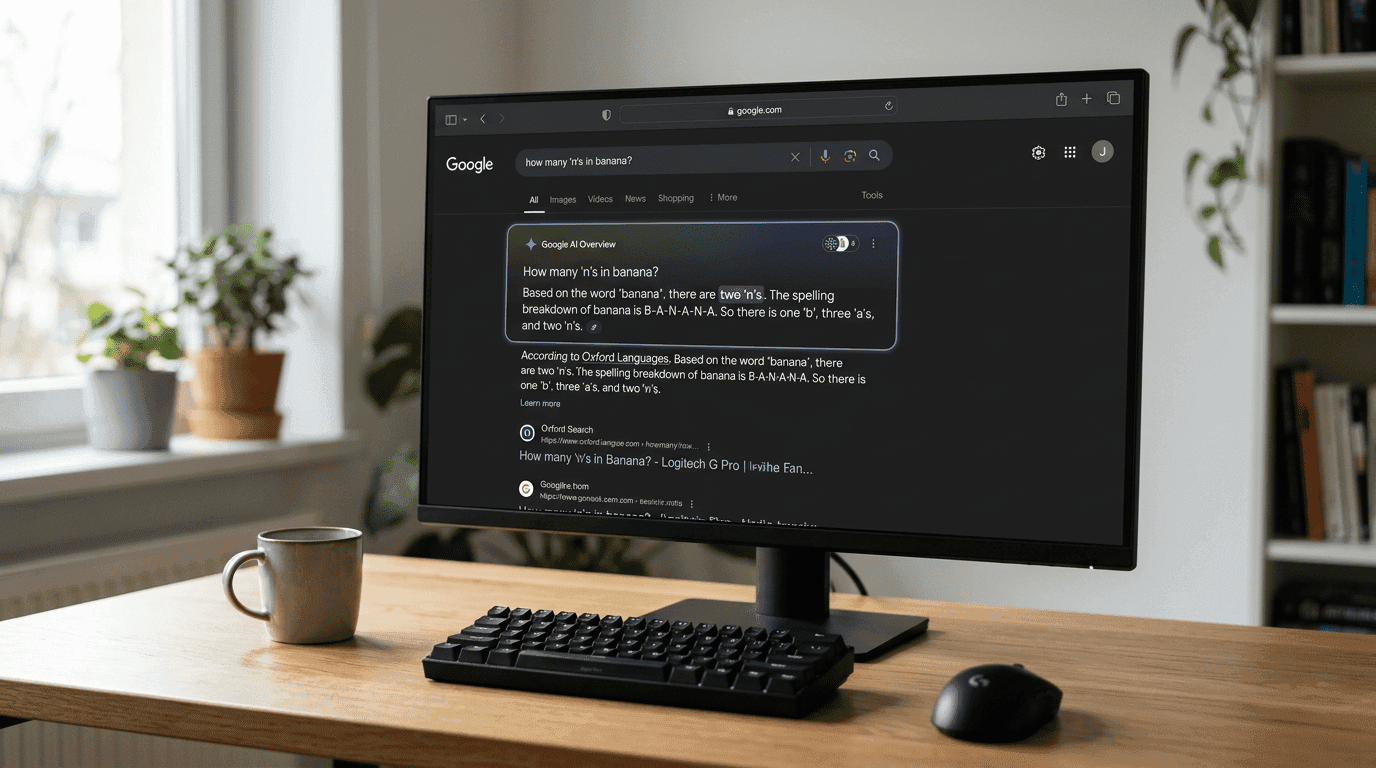
Have you asked Google’s new artificial intelligence to spell a basic word lately? If you ask how many times the letter ‘o’ appears in the word Google, it might get it right. But ask it to count the ‘r’s in strawberry, and the system falls apart. Ask it how many times the letter ‘n’ appears in Lincoln, and the software confidently tells you there is only one.
It feels completely bizarre. We live in an era where tech companies spend billions of dollars building massive supercomputers. These machines can write complex software code in seconds. They can pass medical exams. Yet, they fail a spelling test designed for a first grader.
We knew Google’s new search layout was going to have growing pains. When the company first rolled out AI Overviews, the system made headlines for telling users to eat rocks and add non-toxic glue to their pizza. Those dangerous tips forced Google to scale back some features. Now, as the company doubles down on making artificial intelligence the center of its flagship product, users are finding a new wave of funny, persistent errors.
The spelling mistakes are a running joke in the tech community. But the reason behind this failure reveals a lot about how these systems actually operate.
The Blind Spot in the Machine
When you look at a word on a screen, your brain recognizes the individual letters. You see the shapes, sound them out, and combine them into a concept. Artificial intelligence does not do this. Large language models do not see letters at all. They rely on a system called tokenization.
Instead of reading a word letter by letter, the software chops text into tiny chunks called tokens. A token might be a whole word, a single syllable, or just a common grouping of letters. The AI assigns a specific number to each token. From that point on, the machine only sees the math. It processes these numbers through massive neural networks to predict which number should come next in a sequence.
Matthew Guzdial, an AI researcher and professor, explains that this translation process creates a massive blind spot. When the system looks at the word strawberry, it does not see a collection of ten letters. It sees a single encoded concept. The model understands what a strawberry is, and it knows what sentences usually contain the word strawberry, but it literally does not know how the word is spelled. It lacks the basic architecture to count the characters inside its own tokens.
Speed Over Accuracy
Researchers point out that fixing this specific flaw is incredibly difficult. Christian Picado, a PhD student studying how language models work, notes that getting experts to agree on how a model should process individual letters is a massive headache. Tokenization makes the software incredibly fast and efficient at generating long paragraphs. If developers forced the AI to read every single letter one by one, the system would slow down to a crawl. The spelling errors are simply the price we pay for speed.
Google representatives admit that spelling and character counting remain known challenges for their large language models. They are working on patches, but the underlying structure of the technology makes this a stubborn problem to solve.
These silly spelling mistakes serve as a great reminder for all of us. When an AI gives you an answer with extreme confidence, it is still just guessing the next most likely token. It does not possess real knowledge. It does not reason. It just predicts patterns. So, the next time you need a quick summary of a long report, the AI can help. But if you need an exact character count, you should probably just count the letters yourself.